
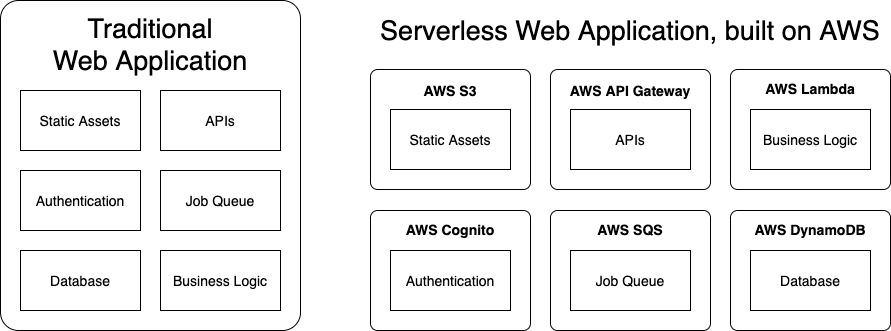
My latest client web project was built on a serverless architecture. It used VueJS on the frontend and a variety of AWS services on the backend. This included DynamoDB as a database, AppSync for graphql endpoints, Cognito for user authentication, and Lambdas (written in Go), for backend logic.
Setups like these have become increasingly popular over the years, but this was my first time working on the infrastructure side of one. In this article, I want to reflect on the experience and explore how serverless fits into the broader architecture discussion.
What Makes Serverless Serverless?
For years, the most common way to host a website was to rent a server (often a virtual machine) from a hosting company. Usually, a monthly fee would give you full ownership over a server on the network to use however you want. Serverless is an alternative approach, where the hosting company manages the servers while providing targeted services you can use, and pay for, on-demand. A popular example is cloud functions (like AWS Lambdas), which can execute arbitrary code for a single web request.
You can build massive websites like this, stitching together various services to handle data storage, authentication, APIs, and more. Indeed, our client was building a whole platform on these services, which they used to serve websites, provision smart devices, manage customer data, and more.
The Promise of Serverless
A common claim of serverless is that it allows you to “focus on your application, not the infrastructure.”
That’s compelling! But is it true? As far as I can tell, the claim is justified like this:
It’s lower maintenance because the vendor manages the servers for you.
It scales automatically because the vendor handles scaling for you.
I experienced some of these benefits first hand. When big parts of our client’s platform went live, the services scaled beautifully to handle the demand, even with the demand being greater than expected. That could have been a painful process in a traditional hosting setup.
But there were other ways in which the promise of serverless fell short for me. I expected to be able to focus on the application when, in reality, I was constantly managing infrastructure.
For example, if I wanted to add a new API endpoint, I’d spend the majority of my time changing AWS config, provisioning new Lambdas, applying the right roles and permissions, and testing that all the services were talking to each other properly. Dividing our application into AWS services meant that application development and infrastructure work were essentially the same thing.
Manually configuring AWS services can be tedious and error-prone, especially if you need to deploy those updates to multiple regions or environments (like we did). In our case, we leaned on a tool called Terraform to help us define AWS configuration in code, commit it to our codebase, and run repeatable deployments. Terraform was incredibly helpful, but it came with its own language and learning curve to deal with. And at the end of the day, spending my time hand-editing cloud configuration files felt like a far cry from “focus on your application, not the infrastructure.”
Moving the Complexity
The more I worked with serverless, the more I felt like it was moving the complexity instead of removing it. Instead of provisioning servers, I was provisioning cloud resources. Instead of updating operating systems, I was updating lambda runtimes and Terraform versions.
Now don’t get me wrong: moving the complexity can be a great thing. If your team doesn’t have experience scaling traditional infrastructure, then moving that complexity to the vendor is a huge benefit. Cloud SLAs can bring peace of mind, and peace of mind is worth a lot.
But if technical decisions are all about trade-offs, then serverless is no exception. Local development with serverless can be painful or even impossible depending on your setup. And you’ll need to spend some effort finding ways to deploy and monitor your systems.
Could better tools address these issues? Maybe! Serverless is still a pretty new concept, and the ecosystem is rapidly evolving. I’m looking forward to seeing how future products and frameworks can improve these kinds of workflows, especially around local development and deployments.
When Should We Reach for a Serverless Architecture?
I can think of several situations where serverless could work really well.
On one end of the spectrum, if your project only needs a tiny bit of backend computation, using a Lambda or two would be a lot less overhead than setting up a whole web server. For example, an online tool like Sassmeister or Try Ruby is mostly frontend but still needs a place to execute the Sass or Ruby code. A Lambda seems perfect for that (especially if the tool becomes popular).
On the other end of the spectrum, I think it could be a great fit for certain kinds of large projects with the following conditions:
You anticipate the need to scale
You expect to scale beyond what vertical scaling can easily provide.
You don’t want to build out a dev-ops team dedicated to designing and monitoring a horizontal scaling infrastructure by hand.
You have needs that lend themselves toward specific cloud services (like Internet of Things support, Machine Learning, or distributed databases).
When it comes to mid-sized projects… I’m not so sure. Vertical scaling is more of an option with mid-sized projects, and it’s often manageable without a dedicated team. If you really need to scale horizontally, then you can go with hosting services (like Heroku and Google App Engine) that have autoscaling built-in without requiring you to divide your app into separate services. Of course, these options also have their trade-offs, including the potential for higher costs.
I’m sure my perspectives will shift over time as the industry evolves and more people share their experiences working with serverless. To that end, I hope that the experiences I’ve shared in this post contribute to your own understanding of serverless and where it fits into the broader development ecosystem.
