
Writing software that meets our clients’ business needs often highlights the importance of time. Time manifests in deadlines, is the primary measurement of features from conception to production, and directly translates to money spent. Often complexity is measured and talked about in reference to time (and complexity is certainly a large factor in the time it takes to develop features or to fix bugs).
Want to move up timelines for new feature development or for bug fixes? We’ll share the strategies we’ve used to identify and smooth out the complexity in development cycles.
How Can We Move Faster?
A common suggestion is to add more developers to the team. In many cases, this can help, but the “The Mythical Man-Month” shows that throwing more developers at a problem will not always make it go faster. So how do we go faster when a larger team isn’t helping? How do we avoid bottlenecks and blockers from other teams? Can developers make progress in parallel without being blocked by other developers? The answer to most of these questions is to start thinking about the seams in your project.
Reducing Blockers by Looking at Seams
At Sparkbox a “seam” is where multiple team’s work comes together or technically the boundary between two services (usually where these services communicate). The most common and obvious seam in a full-stack web application is the seam between the frontend and the backend. The frontend is generally the technology and code that makes up the visible part of the page or application. The backend is usually the server-side code that handles business logic and delivers the frontend code to the client. (For the purposes of this article, I’m not going to delve into front-of-the-front.) Traditionally, the backend has been a blocker to the frontend since the frontend relies on (and has to wait on) the backend for delivery, business rules, and data. Here are some strategies to get the frontend team unblocked by the backend team and get the two teams working in parallel. This type of “seam thinking” works between any two teams, but it’s easier to discuss the canonical seam in web development.
Decomping
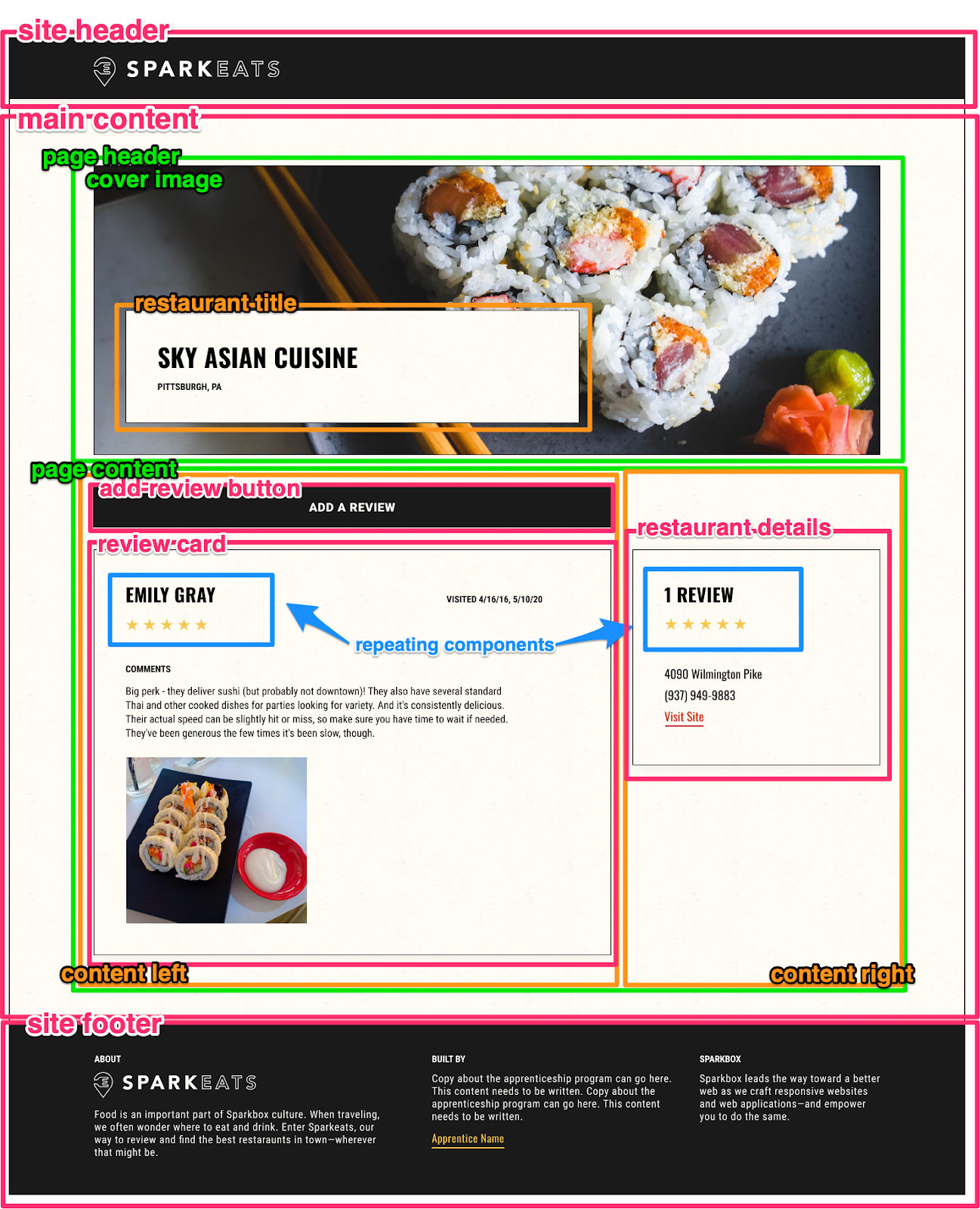
Regardless of the strategy or even the team composition, at Sparkbox, we’re big proponents of what we call “decomping.” This is a valuable tool in the planning phase of a project. “Decomping” is taking a design or wireframe of an application and breaking it down into manageable chunks. An example would be a page that shows a grid or list of products. We can break that grid down to a grid of product card components that are composed of smaller components like product images, product titles, etc. Or this example of a decomped food review page for SparkEats.
Doing this exercise illustrates the scope of work for the frontend team, highlights assumptions around cross-team communication and data flow, and highlights the data requirements for the backend team. There’s no special tool for decomping; we’ve used physical printouts of a design, screenshot tools, and Figma/Sketch/Photoshop. Any tool that can communicate a box and what is contained in that box works great. We’ve had good experiences with draw.io, Figma, and Miro. Just about every time we do this exercise, it helps the team move faster because it is just so much easier (and cheaper!) to iterate on ideas and solutions outside of code.
Static Data
This one is pretty straightforward. Have the frontend team use static (“dummy”) data in place of interacting with the backend system. This removes the backend team blocking the frontend team. However, this adds two new steps to the work:
Coordinating between frontend and backend teams on the shape of the data
Integrating the frontend and backend systems at some point in the future when both systems are ready to go
Tactically, this could look like having a static file that is imported into the codebase in place of the backend call. These strategies and ideas build on each other. The next tip is to take this static data and create a fake API out of it.
Static Data as an API
Use something like json-server to serve the static data from the previous step as a fake API. This would allow the frontend team to write the API calls that fetch data without needing that API to be finished. However, the tradeoff remains the same: your backend and frontend teams need to coordinate on the data contracts. This underscores how useful a decomping phase is: it facilitates this coordination from the get-go. A fake API with static data is still quicker than having the work happen linearly, and it probably will expose holes in the data logic earlier in the project. This naturally leads to exposing the API host and other infrastructure as environment variables, which leads us down the 12-factor happy path. Our experience using a fake API like this is that it unlocks the frontend team on two fronts:
The frontend team no longer has to run the actual API locally or figure out authorization to connect to it remotely.
Frontend work can begin much quicker without having to wait for the backend to be implemented.
Another version of this “fake API” approach is to have the backend team use static data with the real API. This approach allows the backend team to focus on their own backend work while the frontend team uses something that is closer to the real thing than a truly fake API with json-server or something similar.
Development Resources
So far, we’ve focused on projects that have clear backend and frontend seams. Not all projects have those seams. On projects that are IoT, computing at the Edge, or based entirely on a public cloud like AWS or Azure, the concept of staging or a dev environment is challenging. One approach would be to spin up backend resources as a sandbox for the development team. Tools like Docker are great to make local sandboxes that are identical to production environments. Tools like terraform let us create sandboxes on the exact same cloud infrastructure, such as AWS or Azure. This approach can extend to sandboxes for various types of accounts that mimic production, but the team can scaffold up and tear down these sandboxes easily. We’ve worked on projects that were entirely composed of microservices running in AWS Lambdas. It’s not easy to run a Lambda locally, so instead, we used Terraform to quickly scaffold isolated AWS sandboxes for each developer to test in. The benefit of Terraform was that these sandboxes could quickly be destroyed and rebuilt again if testing went awry.
Investigating Assumptions
The methods and ideas presented here are ways we’ve had success on projects, but this isn’t an exhaustive list of every way to move up timelines. Each project and team has their own unique blockers and seams. Whether your team uses static data or individual dev sandboxes, it’s important for you to recognize and validate the assumptions introduced. Those assumptions are a risk, but you can take the opportunity to address those assumptions early in the project. At Sparkbox, we are always examining our own workflows and our clients’ workflows to identify ways to unlock better feedback loops while retaining confidence that we’re building the “right thing” and building it in a way that makes the web better.
Sparkbox’s Development Capabilities Assessment
Struggle to deliver quality software sustainably for the business? Give your development organization research-backed direction on improving practices. Simply answer a few questions to generate a customized, confidential report addressing your challenges.
