
Minimum Viable Product (MVP) is awesome when it works. This past year, one of our clients, Once a Month Meals (OAMM), had great success transforming their popular food blog into a full-fledged SaaS application that made customizing monthly meal plans a breeze. OAMM gives users preset meal plans based on dietary choices, but the application allows users to swap out meals in the plan and choose how many people they are cooking for, and then they are given all the tools and resources they need to cook everything in one day. As you might expect, search was a fundamental part of making this application work for customers. Since the dataset was limited, we were able to implement a client-side search solution very quickly within the existing EmberJS application.
Fast forward 12 months, the dataset had grown, and we understood our customers’ needs more clearly. In response to this new, more mature stage, we pushed our live search to the server with some incremental features. And we completed this transition while maintaining the live, incremental search customers had come to expect.
Solr and Sunspot
While simple text search got the product to market, our client had come to the conclusion that targeting recipes by ingredient, diet, and cooking method was what customers really need. To address this, we turned to Solr, a powerful search platform built on Apache Lucene, which integrated well into our Rails API stack using the Sunspot gem.
There are plenty of guides to get started with Solr and Sunspot, but I wanted to delve into how we prepared for our migration to Solr and the customizations we made to improve the usability of our search.
Creating a Seam
The initial modification of our Rails API to accommodate server search was done entirely in the Rails Controller. We composed an Active-Record query expression where criteria were specified:
def search
...
recipes = recipes.fuzzy_name(term) unless term.blank?
recipes = recipes.tagged_with(with_tags, all: true) if with_tags.present?
recipes = recipes.where(:meal_type => meal_type) if meal_type.present?
recipes = recipes.paginate(per_page: page_size, page: page)
render json: {
recipes: ActiveModel::ArraySerializer.new(recipes),
meta: { ... }
...
end
As we prepared to move search to Solr, we implemented a very simple seam in the controller by moving the search to a Query Object:
def search
...
search = RecipeSearchQuery.new term: params[:term],
with_tags: with_tags,
meal_type: meal_type,
page_size: page_size,
page: page
render json: {
recipes: ActiveModel::ArraySerializer.new(search.results),
meta :{ ... }
}
...
end
That gave us one place where searching was isolated, and it was at the boundary of our architecture—much easier to replace.
Canary Deployments
Canary deployments involve deploying new functionality to a portion of the audience to verify assumptions. In our case, we knew that Solr search had the potential to provide slightly different results for various reasons, and we wanted to see how this new functionality faired before a mass deployment.
Since we had a seam, we could deploy our A/B style switch at that location for both the legacy and Solr queries. Here’s a very naive A/B switch using Random:
def search
...
search = query.new term: params[:term],
with_tags: with_tags,
meal_type: meal_type,
page_size: page_size,
page: page
...
end
def query
query_engine = RecipeSearchQuery
search_source = (ENV["SEARCH_SOURCE"] || "legacy").to_sym
if search_source == :solr
query_engine = RecipeSearchSolrQuery
elsif search_source == :mixed
query_engine = (Random.rand(9999) % 2 == 0) ? RecipeSearchSolrQuery : RecipeSearchQuery
end
query_engine
end
Actual usage may suggest Solr wasn’t the right choice. But we were in a better place to make changes if that were the case, because we could take a very deliberate step in evolving our search functionality rather than assuming our next search implementation was the correct choice.
Partial Matching
Out of the box, Solr provided word stemming to make searching for “cherry” include results for Chocolate Covered Cherries. This was a big improvement over our legacy search, but we regressed by not supporting partial matches for cher. Users expect results as they type, and we wanted to continue providing that functionality.
This involved updating indexing and query configuration in Solr/Lucene. Figuring out the right configuration required a bit of trial and error. Luckily, Solr’s admin interface provided a great tool for decomposing both the indexing and query sides of Solr.
Sunspot’s default Solr schema for text fields looked something like this:
<!-- *** This fieldType is used by Sunspot! *** -->
<fieldType name="text" class="solr.TextField" omitNorms="false">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StandardFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
This meant Solr/Lucene would break the data down by words in lowercase, while the PorterStemFilter would provide word stemming (a huge feature). When we used the Solr Analysis tool, we saw the following for text field analysis:
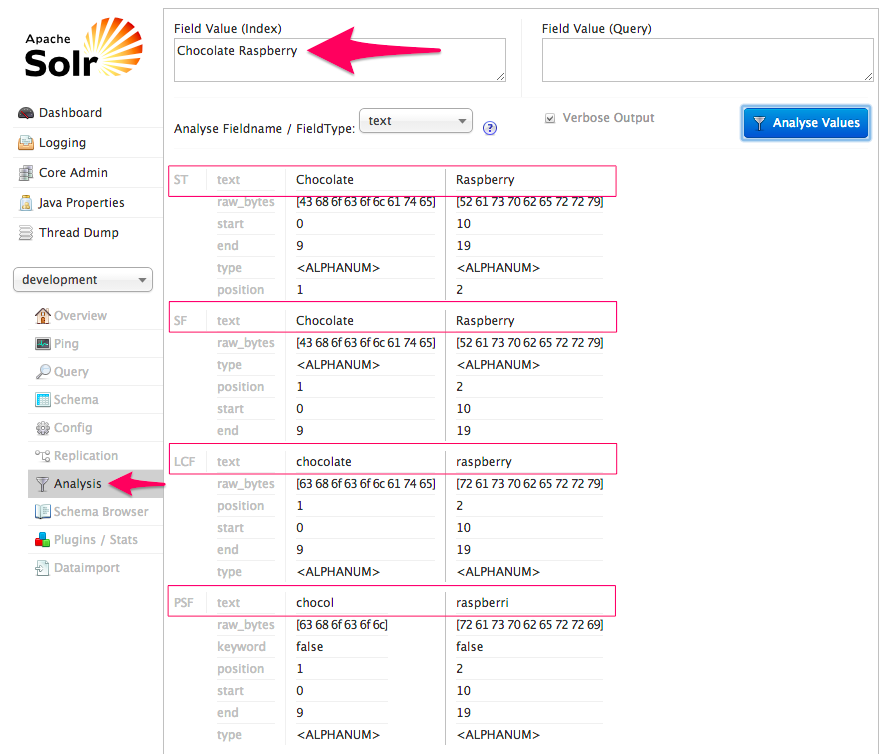
Looking at the results above, we saw each word broken up and processed using the filter pipeline in our configuration:
ST = Standard Tokenizer
SF = Standard Filter
LCF = Lower Case Filter
PSF = Porter Stem Filter
After flowing through each filter, the resulting terms were chocol and raspberri. This might seem odd at first, but hang in there.
For partial matching to work with Solr, we needed to create what are called NGrams. N is a placeholder for the number of Grams we want. Let’s see what we get when we configure Solr with the NGramFilterFactory.
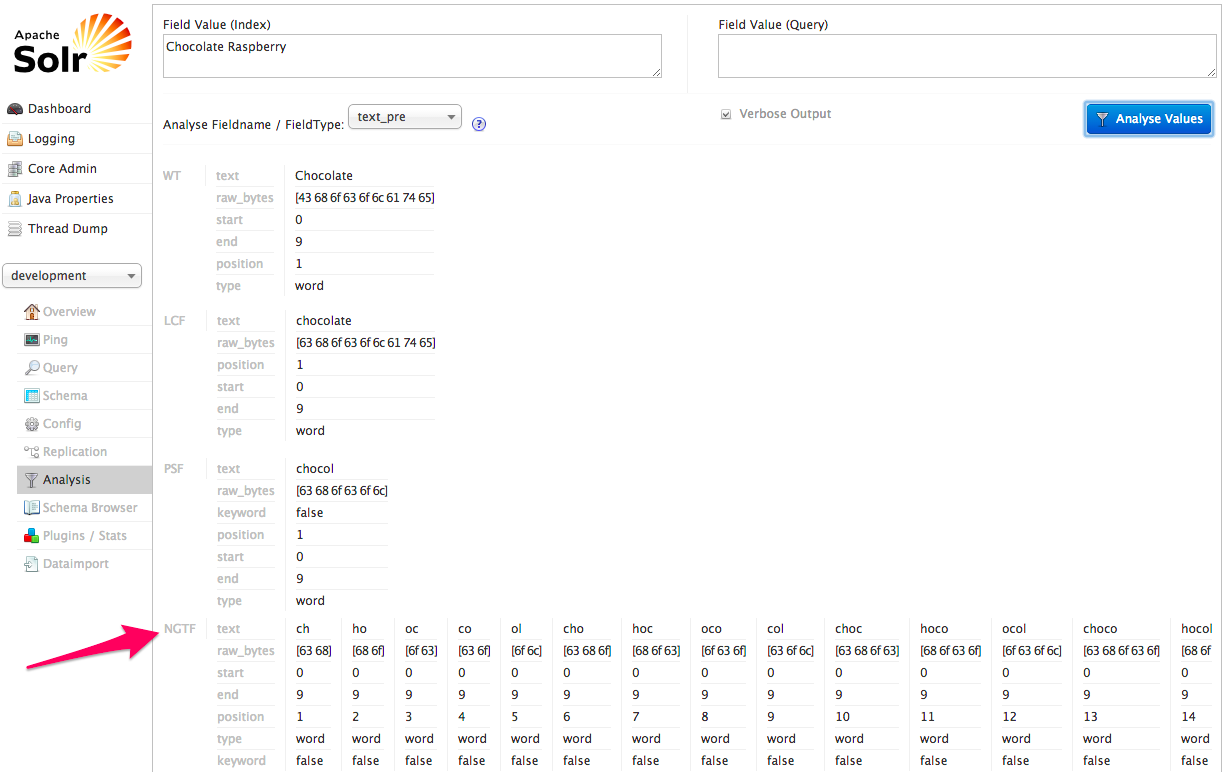
Slow down there, Batman! What is all of that?
The first three sections should look familiar, but now we see that Solr has reported a progressive breakdown of the terms into 2 character and 3 character bunches. If we were to keep scrolling, we’d see 4, 5, and larger bunches as well. We’ve provided Solr (Lucene, really) with more values to match our searches.
Our final Solr schema.xml looked something like this:
<!--...-->
<fieldType class="solr.TextField" name="text_partial" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
<filter class="solr.NGramFilterFactory" minGramSize="2" maxGramSize="15"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<!--...-->
We only wanted certain model attributes marked with as: ‘text_partial’ broken down in this way, because they add disk space and bulk indexing speed implications. For those attributes, we offered partial and stemmed search results.
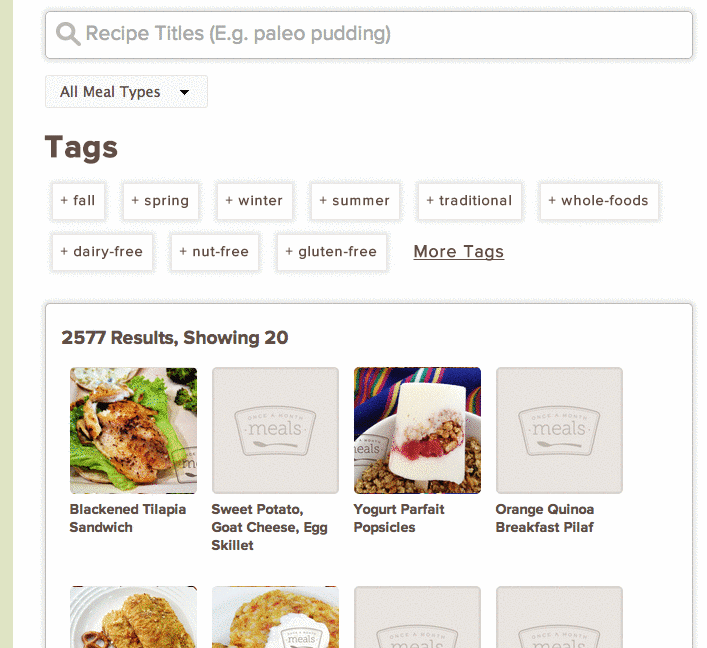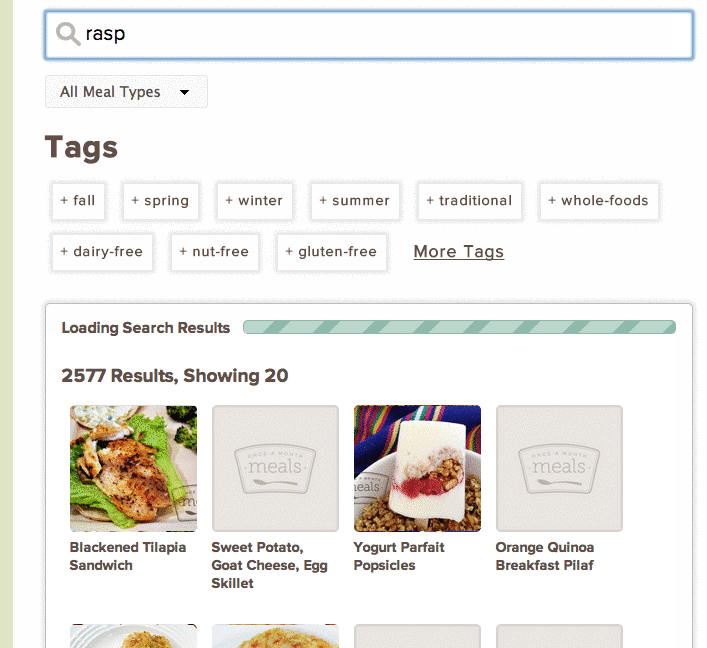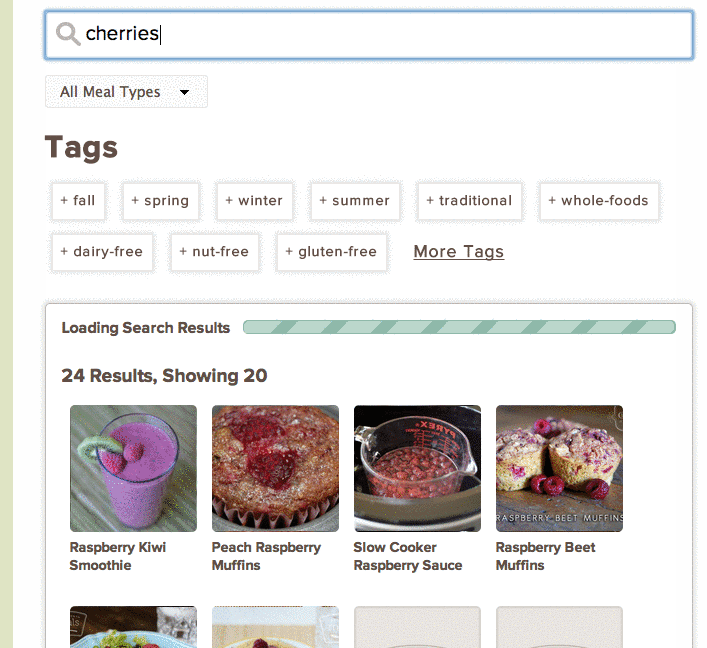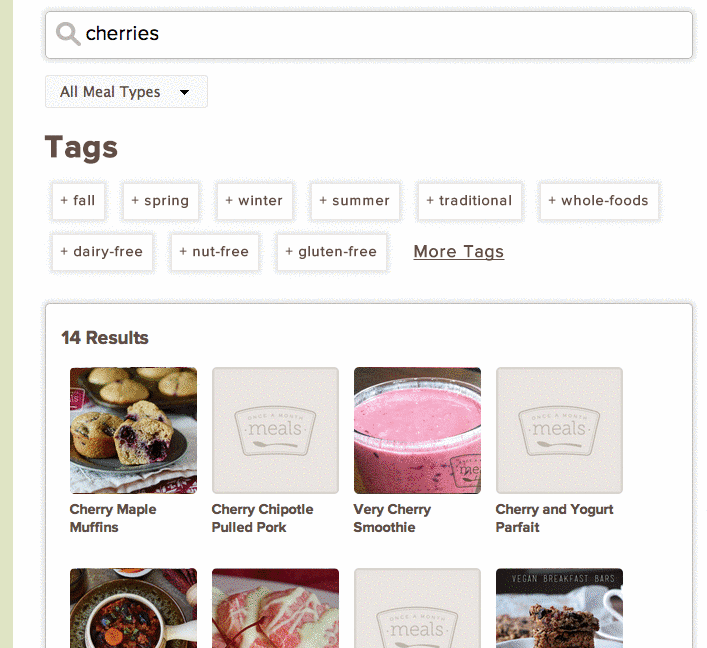
Opportunities
With Solr in place, using a Canary deployment style, we have the ability to watch users’ reactions to what we assumed would be a better search experience. Once we’re comfortable with our implementation and configuration, we can deploy to all users.
As we move forward, data that is more complex to query and filter using the relational data store can be indexed using Solr. Users will continue to see great search response times even while we turn up the capabilities, and we’re excited to keep working with a great partner like OAMM who uses technology to make it easy to get families around the table.
